
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] 输出:[1,2,3,7,8,11,12,9,10,4,5,6] 解释: 输入的多级列表如下图所示:扁平化后的链表如下图:
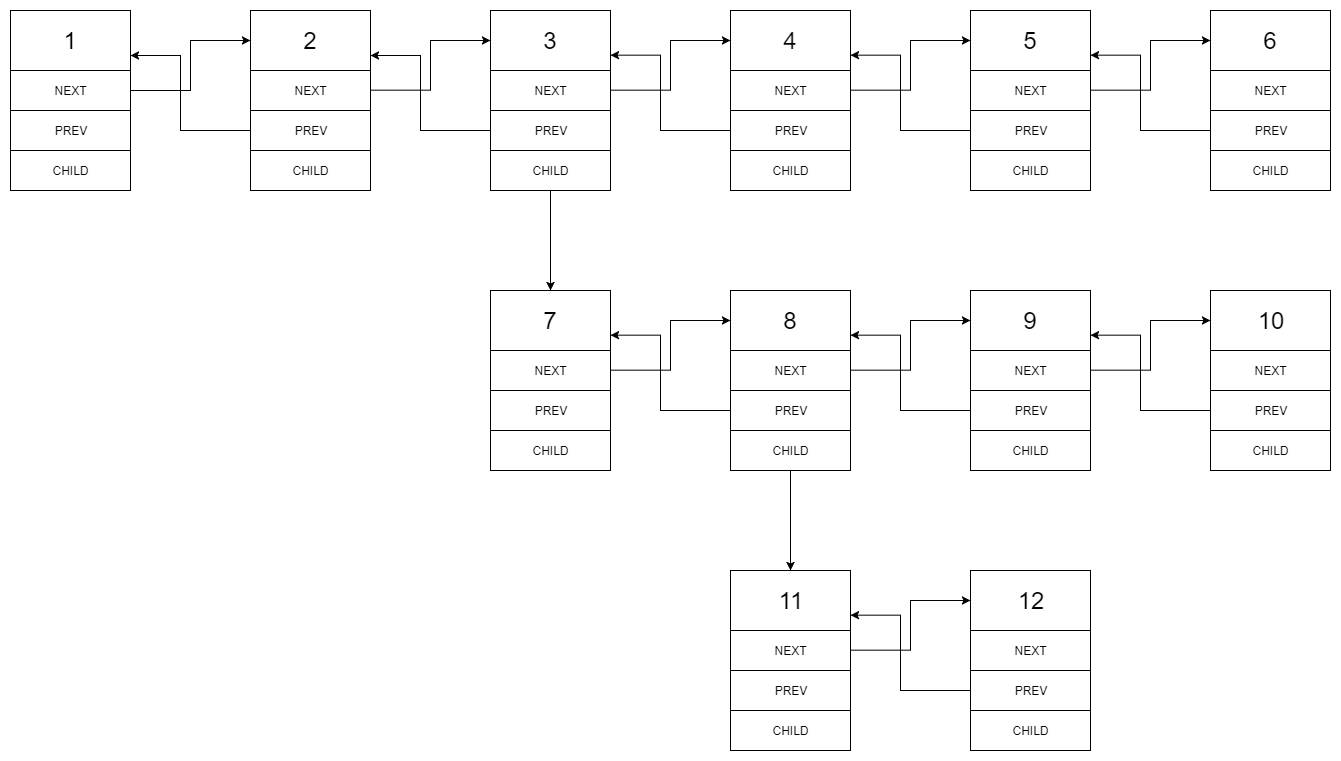 扁平化后的链表如下图:
扁平化后的链表如下图:

示例 2:
输入:head = [1,2,null,3] 输出:[1,3,2] 解释: 输入的多级列表如下图所示: 1---2---NULL | 3---NULL
示例 3:
输入:head = [] 输出:[]
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null] [null,null,7,8,9,10,null] [null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
提示:
- 节点数目不超过 1000
1 <= Node.val <= 10^5
**难度**: Medium
**标签**: 深度优先搜索、 链表、
# -*- coding: utf-8 -*-
# @Author : LG
"""
执行用时:36 ms, 在所有 Python3 提交中击败了97.99% 的用户
内存消耗:14.7 MB, 在所有 Python3 提交中击败了5.05% 的用户
解题思路:
指针+递归
具体实现见代码注释
"""
class Solution:
def flatten(self, head: 'Node') -> 'Node':
result = Node(0) # 用于保存结果
self.node = result # 指针指向当前处理节点
def find(head): # 递归
if head:
head_next = head.next # 保存当前节点next和child
head_child = head.child
self.node.next = head # 将当前节点插入到指针后
self.node.child = None # 删除child
head.prev = self.node
self.node = self.node.next # 移动指针
find(head_child) # 递归处理child
find(head_next) # 递归处理next
find(head)
if head:
result.next.prev = None # 将结果的prev指向None
return result.next